Hadoop HDFS BlockManager解析
之前的章节说过 FSDirectory 中记录了所有的文件节点信息,而具体的文件内容则被分布式的存储在各个 DataNode 上。
引用:
尽管通过 FSDirectory 我们能够知道每个节点对应的路径的真实路径,但假如我们需要对整个存储块信息进行统一归属,那么 FSDirectory 由于是树状结构的形式,每次查找信息都需要遍历树中的每一个节点,效率太低,因此产生了 BlockManager 负责统一调度 DataNode 的存储消息。
如果把 Hdfs 比喻成一个人的躯干,那么 NameNode 就是他的大脑,了解每一个节点的状态信息,控制并管理四肢( DataNode )的运作。而 BlockManager 则是整个躯干中的心脏,他源源不断的接收来自四肢的血液( BlockInfo), 再反将血液( Command )传输回四肢中,让其能够正常运作。
BlockManager
BlockManager 主要的成员有以下这些:
blocksMap: 虽然已经有了 FSDirectory 类负责维护整个文件系统的树状结构,但在树状结构中进行数据查找的效率较低,在 BlockManager 内部在 blocksMap 中维护了一个定长的数组,在 Block 类中通过重载 hashcode() 函数,实现 blockId 和 hash 码的一一对应,确保不会出现多个 block 对应同一个 hash 码的情况,使得从 blocksMap 中取数据的时间复杂度为 O(1) 。
DatanodeManager: BlockManager 负责接收管理来自 DataNode 的消息,具体的管理操作由 DatanodeManager 接管,他负责监控 DataNode 节点的状态变化以及消费 Block 信息变化指令。
DocommissionManager: 管理需要退役或检修的节点信息,在确保这些节点上的数据都被成功转移后,才将节点置为退役和检修状态,避免直接设置导致的数据丢失。
DataNode的三板斧 register heartbeat reportBlock
DataNode 与 NameNode 之间是一个单向通信模型。NameNode 为了保证运行效率,不会向 DataNode 主动发起通信请求,因此通信所有行为都是由 DataNode 主动发起。
DataNode 针对每个 NameNode 节点会单独启动一个 BPServiceActor 的线程对象,这个对象负责同 NameNode 建立通信链接,并定时发送心跳和存储块信息。
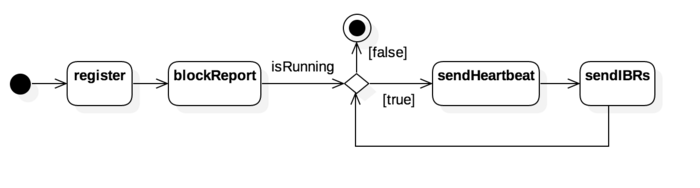
如图所示,启动 BPServiceActor 后,首先向 NameNode 进行 register, 之后会进行一次完整的节点存储 block 信息上报,然后进入心跳流程,定时通过 sendHeartbeat 告知 NameNode 当前节点存活,如果有发生块信息变动,则在发送心跳之后,会尝试 sendIBRs (increment block report) 发送增量的块信息变动情况。
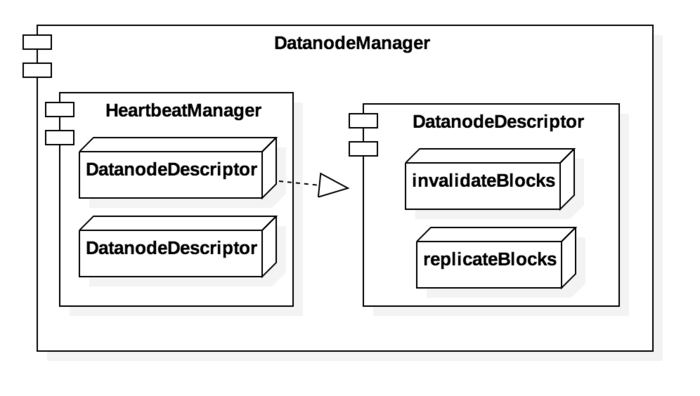
Register
当接收到来自 DataNode 的 register 请求后,会依据传递过来的 DatanodeRegistration 构造出一个 DatanodeDescriptor 对象,并放入 HeartbeatManager 中的数组中,此时我们认为 DataNode 节点已经在集群中注册完毕,但这个节点中究竟有哪些 Block 信息仍然是未知的。
BlockReport
DataNode 通过 blockReport 之后,在 BlockManager::processReport 对上报的 Block 信息进行消费1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public boolean processReport(final DatanodeID nodeID,
final DatanodeStorage storage,
final BlockListAsLongs newReport,
DatanodeStorageInfo storageInfo = node.getStorageInfo(storage.getStorageID());
if (storageInfo == null) {
// We handle this for backwards compatibility.
storageInfo = node.updateStorage(storage);
}
if (storageInfo.getBlockReportCount() == 0) {
processFirstBlockReport(storageInfo, newReport);
} else {
invalidatedBlocks = processReport(storageInfo, newReport, context);
}
storageInfo.receivedBlockReport();
}
DataNode 节点上可能有多个存储位置用于存放 Block 数据,对于每个存储位置,都有一个 DataStorage 对象和他对应。在 BlockManager::processReport 会以 DataStorage 为单位进行消费。
1 | private Collection<Block> processReport( |
需要留意的是 FoldedTreeSet 是一个基于红黑树构造的 BlockReportReplica 遍历器,如果发现在 DataNode 端没有预先对 report 进行排序,则在这里会对 report 进行再次排序,方便在 reportDiffSorted 中对上报的 Block 信息进行筛选。
- 在 reportDiffSorted 中会对当前上报的 Block 进行分类,分别拆到不同的 List 中,其中:
1) toAdd: 被认为是正式数据,需要同 BlockInfo 进行关联的数据
2) toRemove: replica 的 blockId 比节点中的 blockId 更大,认为是无效数据
3) toInvalidate: 已经被 NameNode 移除的节点的 Replica 文件,需要通知 DataNode 移除数据
4) toCorrupt: 与其对应的 Block 对应的节点存在,但数据和节点中的描述数据存在差异,被认为是无效数据
5) toUC: 数据正处于写入过程中,等待后续写入完毕
对上报的 Block 进行解析处理之后,会根据其具体类型作出对应的处理操作,所有数据处理完毕之后,整个 Storage 的 block 信息对于 NameNode 就是已知的。
Heartbeat
每次 DataNode 发送心跳后,都会在 HeartbeatManager 中更新其最近的访问时间,用以识别该节点仍旧存活。
在 DatanodeDescriptor 中有多个集合,以 invalidateBlocks, replicateBlocks 为例,他们分别代表着已经废弃的 Block 和 需要向其他节点进行备份的 Block。 在更新完毕心跳信息后,会根据集合信息建立返回指令,告诉 DataNode 在本地节点需要做的行为操作,例如删除无效的 Block 以及向其他节点进行备份操作保证数据冗余度。
同时在 HeartbeatManager 中还有一个 HeartbeatManager.Monitor 线程,通过轮询 heartCheck() 检测是否有 DataNode 过期。一旦发现有节点过期,则将其从 DatanodeManager 中移除,同时也会将其存储空间中的 Block 信息从对应节点中移除,避免无效访问。
Block 容灾备份
为了避免由于节点异常导致的数据丢失, Hdfs 采取多地备份的策略,同时在多个 DataNode 中持有同一份数据。
在 Hdfs 中多副本容灾的策略由两部分组成,首先是在文件首次创建时,通过数据管道同时在多个 DataNode 中创建 Block ,保证创建时就拥有多个副本;其次是在节点因为断开链接或则文件异常损坏的情况下,通过复制现有的副本文件到另一个节点中,保证副本的冗余度。
第一点的数据管道在前一篇文章中已经做过介绍,在这里不再多说。第二点的副本复制策略是通过 RedundancyMonitor 线程进行实现的。1
2
3
4
5
6
7
8
9while (namesystem.isRunning()) {
// Process recovery work only when active NN is out of safe mode.
if (isPopulatingReplQueues()) {
computeDatanodeWork();
processPendingReconstructions();
rescanPostponedMisreplicatedBlocks();
}
TimeUnit.MILLISECONDS.sleep(redundancyRecheckIntervalMs);
}
在RedundancyMonitor的循环中,主要执行了computeDatanodeWork、processPendingReconstructions、rescanPostponedMisreplicatedBlocks三个方法。
computeDatanodeWork
1 | int computeDatanodeWork() { |
BlockManager 中有一个 LowRedundancyBlocks 对象负责记录那些副本数量较低的 Block 信息,在 LowRedundancyBlocks 中有一个 priorityQueues 的优先级队列,队列按照当前副本数量进行排列,急需备份的 Block 会被优先取出来中进行消费。
这里我们需要知道,当前节点异常或某个 Storage 上保存的文件异常时,会对受到影响的 BlockInfo 进行分析,如果发现副本数量不足,则会加入 priorityQueues 队列中,等待节点进行备份。
computeDatanodeWork 会先从 priorityQueues 取出指定个数的高优任务,将其加入 DatanodeDescriptor 的 replicateBlocks 集合中。然后再从 BlockManager.invalidateBlocks 中拿到被移除的无效文件的 Block 信息,加入 DatanodeDescriptor 的 invalidateBlocks 集合中。
当 DataNode 发送心跳信息到 NameNode 时,会从对应的 DatanodeDescriptor 中取出 replicateBlocks 以及 invalidateBlocks,分别对应需要进行再次备份和已经无效的 Block 块,将其作为返回信息,返回给 DataNode 进行内部处理
processPendingReconstructions
1 | private void processPendingReconstructions() { |
pendingReconstruction 中存放着一些 NameNode 认为正在进行数据生成的 Block 信息,如果长时间等待之后,发现 Block 的数据还没有生成完毕,就将对应的 Block 信息再次放入 pendingReconstruction 中,等待其他 DataNode 进行数据生成。
rescanPostponedMisreplicatedBlocks
1 | void rescanPostponedMisreplicatedBlocks() { |
由于数据在多个节点中进行传输,无法实时在 NameNode 的内存中进行查看,因此有时候我们无法确定某些 Block 具体处于什么状态,此时就会返回一个 MisReplicationResult.POSTPONE 结果,将 Block 再次加入回等待队列,直到能够完全确定块状态,再在 processMisReplicatedBlock 中对其进行处理。
未完待续…